How to design a rate limiter?

 in 4k who is coding and thinking about vectors on a day with bright sunset, and hyper realistic feeling with orange and teal filter.")
What is a rate limiter?
In today’s world, there is an abundance of computers with connectivity to the Internet—an influx of requests to the software we use is a second-order consequence of the phenomenon.
A rate limiter is a critical mechanism designed to prevent users (a.k.a. clients) from making an excessive number of requests to a service or API within a specified timeframe. It is the gatekeeper that controls the throughput to the service by enforcing a request threshold (frequency) in a time frame.
Rate limiters can be implemented with various scopes, tailoring their enforcement to specific identifiers such as per user, per IP address, per API key, or device.

Why do we need a rate limiter?
Improved Security: It is primarily a defense mechanism against DoS or DDoS attacks that usually aims to overwhelm a server with high volume of requests, thus making it unavailable to legitimate users. Moreover, it helps in managing the resource utilization and preventing what’s called resource starvation.
Improved User Experience: When we limit malicious attacks like DoS, brute force attacks, and web scraping, it’d help us improve the user experience with improved responsiveness and reduced delays.
Improved Cost Savings: Lastly, for our services operating on metered cloud resources, rate limiting is a vital tool for cost control, preventing unexpected charges that could arise from overuse or misconfigured client applications.
A DDoS attack is like a huge, coordinated crowd of people trying to rush into your party all at once to make it crash and stop everyone else from getting in.

Functional Requirements (the What)
A functional requirement defines what the system must do (or does)—the core. Here are the functional requirements for a rate limiter
Client Identification: A fundamental aspect of the rate limiter is its ability to accurately identify the client making a request. This identification is crucial for applying specific rate limits tailored to individual users, applications, or sources (you wouldn’t want to rate limits from your competitors’ clients)
Throttling Logic: Once a client is identified, the rate limiter applies its core logic:
If the number of requests from a client surpasses the defined throttling threshold (say 10 requests), the rate limiter must decisively reject the incoming request.
Upon rejection, it is standard practice to send an HTTP "429 Too Many Requests" status code back to the client. This status code communicates that the client has exceeded its allowed request rate.
Ideally, the response should also include specific HTTP headers, such as retry-after, indicating when the client can safely retry their request without exceeding the limit.
Request Forwarding: Conversely, if an incoming request does not exceed the established throttling threshold satisfying all the conditions of the rate limiter, its responsibility is to forward that request to the intended downstream server or load balancer, or service for processing.
Configurability: Your systems are highly flexible and loosely coupled, so should your rate limiter be. This implies the ability to define flexible rate-limiting rules that can vary based on different criteria. For instance, it should be possible to set distinct limits for different clients, specific API endpoints, or even various user tiers (e.g., higher limits for paying customers compared to free users).
Traffic Smoothing - The UX of Rate Limiter
A good rate limiter should possess the capability to "smooth out" traffic spikes. This means that if there is a sudden surge of requests within a short period, the rate limiter should intelligently reject the excess requests to prevent the backend services from becoming overwhelmed.
Non-functional Requirements (the How)
Non-functional requirements (NFRs) describe how a system performs and operates, rather than what specific features it offers. Remember SCALaR(S) from our previous notes?
Scalability
The rate limiter must be designed to handle a large and increasing number of requests, scaling proportionally as the user base expands. We should consider both vertical scaling (enhancing the power of individual machines) and horizontal scaling (adding more machines or instances to distribute the load).
Consistency
In a distributed environment, ensuring consistency is the pulse. All nodes within the rate limiter system must observe the same request count for a given client at any point in time to prevent clients from bypassing limits by distributing their requests across different nodes. Depending on the specific needs of the application, different consistency models, such as strong consistency or eventual consistency, can be chosen.
Availability
High availability is a critical non-functional requirement for a rate limiter. If the rate limiter itself becomes unavailable, it could become a single point of failure (SPoF) for the entire system, potentially blocking all legitimate traffic or allowing unlimited requests.
Latency and
The overhead introduced by the rate limiter must be negligible, ensuring it does not adversely affect the overall system's performance. Requests should be processed and decisions made with minimal delay, ideally within tens or hundreds of milliseconds, similar to the low latency required for a URL redirection service.
Reliability
The system must accurately track and enforce request limits without errors. This demands robust counters, precise logic, and mechanisms to prevent data corruption or inconsistencies, ensuring that limits are applied correctly and consistently.
Privacy
While rate limiters typically do not persist/store highly sensitive personal data, they do handle client identifiers like IP addresses or user IDs. Therefore, they must adhere to general privacy requirements and data handling best practices, ensuring these identifiers are managed appropriately and securely
Fun fact: A system that perfectly achieves maximum scalability, availability, strong consistency, and minimal latency simultaneously is often impractical or prohibitively expensive to build. This fundamental interplay between these traits is important to make an informed design decision for any system you are designing.
Back-of-the-Envelope Calculations
Back-of-the-envelope calculations are usually approximate guesstimations derived from various factors—thought experiments, commonly known performance numbers, and similar systems. The BOE calculations are used to determine that if a system will meet its SLAs or not, although, it’s only an estimation.
Before we jump into calculating the estimates for Rate Limiter, there are a few things that would help us along the way:
Powers of Two: 1 Kilobyte (KB) is 2^10 bytes, 1 Megabyte (MB) is 2^20 bytes, and 1 Gigabyte (GB) is 2^30 bytes.
Latency Numbers: Knowing typical operation times for various components helps in estimating overall response times.
L1 cache references (0.5 ns), main memory references (100 ns), disk seeks (10 ms), and round trips within the same datacenter (0.5 ms).
Availability Numbers: Understanding the "nines" of availability translates directly into acceptable downtime.
99.99% availability translates to approximately 52.6 minutes of downtime per year, while 99% means 3.65 days of downtime annually (a mere 0.99% costs you 5,200 minutes)
Calculation time
We will be considering a hypothetical rate limiter system with the following assumptions:
Scale requirement: ~100 million DAU (Daily Active User)
Request Rate (number of request in the same time frame) : ~ 1000 requests per day
Traffic Estimates
Total Requests in a day: ~ (100 million x 1000 requests per day) = ~10B requests a day
Average Queries per second: 10B requests / (24 hours * 60 minutes * 60 seconds) = ~ 1.15M QPS
Peak QPS: Assuming that you will have twice than the average traffic, it translates roughly to ~ 2.5M QPS
Remember this number to make lives easier when designing a system: 86,400 seconds in a day
On a good day, our rate limiter will receive 10B calls a day, averaging 1.15M queries per second.
Storage Estimates
Questions to ask ourselves: What are we going to store? Didn’t we decide that we will not be storing any sensitive data for good security practices?
We would still need to store a few non-sensitive details for the rate limiter to function properly, such as the last request timestamp, how many requests are left for a user in the threshold
Assume each user's rate limiting state (e.g., remaining capacity, last request timestamp) requires approximately 50 bytes of storage.
For 100 million daily active users, the total storage needed for active users' state would be: 100,000,000 users * 50 bytes/user = 5,000,000,000 bytes = 5 GB per day. This data would ideally reside in an in-memory store like Redis to ensure minimal latency during rate limit checks
High-Level Design (HLD)
High-level designs focus on major components of a system and their interactions, without diving deep into the granular details.
Data Flow
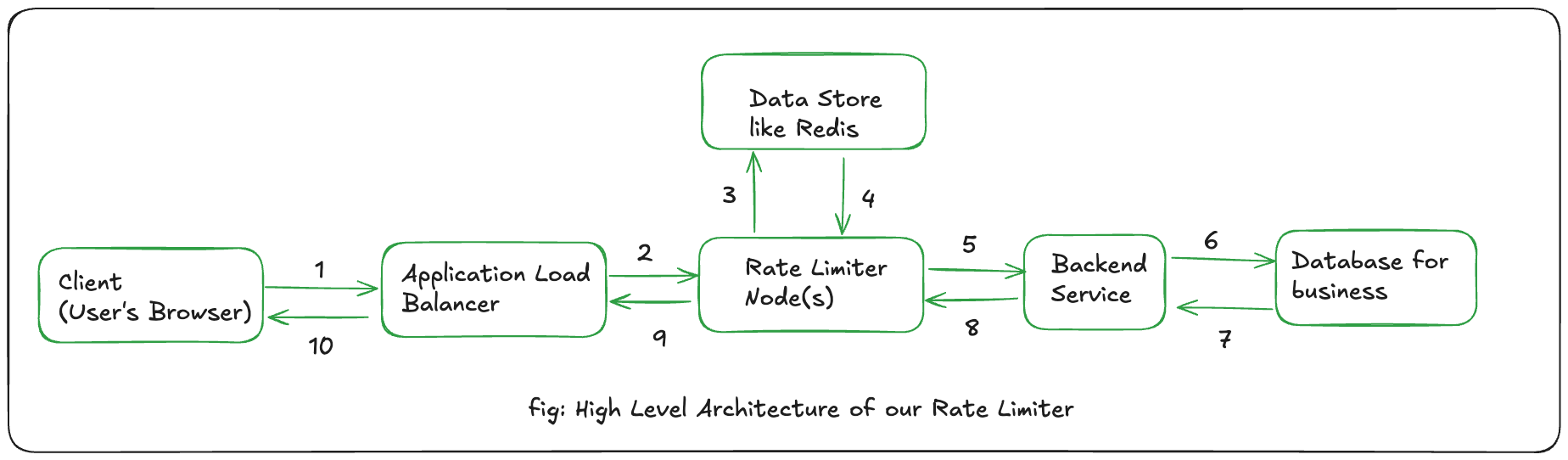
The typical data flow for a request interacting with a rate limiter system begins when a client initiates a request for the service.
Incoming Request: A client (e.g., a user's web browser or another service) sends a request, which includes a client identifier such as an IP address or user ID.
Load Balancer: The request first encounters a Load Balancer. This component is responsible for distributing incoming traffic across multiple instances of the rate limiter service, ensuring even distribution and contributing to overall system availability.
Rate Limiter Node/Service: The Load Balancer forwards the request to an available Rate Limiter Node. This node is where the core rate-limiting logic resides. It receives the request, extracts the client identifier, and then queries a centralized data store (Redis) to determine the current request count or token status for that client.
Centralized Data Store: The Rate Limiter Node interacts with a Centralized Data Store, most commonly Redis, to retrieve and update the rate limit information (e.g., current counts, timestamps, token availability) for the identified client. This store is critical for maintaining a consistent view of limits across all distributed rate limiter nodes.
Rate Check and Decision: Based on the information from the data store and the applied rate-limiting algorithm, the Rate Limiter Node makes a decision:
If the request exceeds the defined rate limit, it is rejected, and a "429 Too Many Requests" HTTP status code is returned to the client.
If the request is within the allowed limit, it is forwarded to the Backend Service.
Backend Service: The legitimate request is processed by the actual application or API service.
Response: The Backend Service generates a response, which is then routed back through the Rate Limiter (potentially for response-based cost accounting) and the Load Balancer to the originating client.
There are different ways that you can deploy a Rate Limiter—as a dedicated microservice, at the API Gateway level, at the application code level (not recommended).
Low-Level Design (LLD)
The Low-Level Design is the specific implementation choices for the rate limiter, including the selection of algorithms and the underlying data structures
Rate Limiting Algorithms
The selection of a rate-limiting algorithm is a crucial decision that depends on specific use cases. For simplicity, we will be exploring one of these algorithms:
Fixed Window Counter
Concept: This algorithm divides time into fixed-size windows (e.g., one minute intervals) and maintains a counter for each window. Every incoming request increments the counter. If the counter exceeds the predefined limit within the current window, subsequent requests are denied until the window resets and a new one begins.
Pros: It is simple to understand and implement, and generally memory efficient.
Cons - Burst Problem: For example, if a limit is 5 requests per minute, a client could make 5 requests at 0:59 and another 5 requests at 1:01, effectively making 10 requests within a very short two-minute span across the boundary, which might be twice the intended rate.
Other algorithms include: Sliding Window Counter, Sliding Window Log, Token Bucket
Bonus: Tools and Programming Languages
Redis: Great for storing rate limit counts quickly because it keeps data in memory and can do atomic operations.
Nginx/Envoy: Act as powerful traffic cops at your system's entrance, enforcing limits before requests even hit your services.
Go (Programming Language): Excellent for building highly concurrent and performant custom rate limiters due to its built-in concurrency features.
Java/Python (Programming Languages): Versatile for developing custom rate-limiting logic within your application, offering extensive libraries and frameworks.
Bucket4j (Java Library): Provides an easy-to-use, in-memory implementation of the Token Bucket algorithm for Java applications.
Follow up
Drop your answers in the comments or shoot me a message
What happens if the centralized rate limiter fails?
How do we deal with that?
How can we design an adaptive rate limiter from this static rate limiter?
Conclusion
From protecting against malicious attacks to ensuring fair resource use, rate limiting is an indispensable guardian in the world of distributed systems. Implementing a robust rate limiter means balancing performance, consistency, and fault tolerance—a true testament to thoughtful system design. So, as you build the next generation of scalable applications, remember: intelligent throttling isn't just a feature, it's the bedrock of stability and user experience.
P.S. Recently, I had a chance to implement rate limiting at the API level. When I was doing so, I had a question: “How does rate limiting work in scale?”. This note is a byproduct of my question! Enjoy reading :)
Great article! 👏 I really appreciated the way you broke down the concept of rate limiting—it’s often misunderstood or overlooked, but you made it approachable and practical. The illustrations you used were spot on and helped visualize how each component fits into the bigger picture. Your step-by-step explanation of implementing a rate limiter was clear, informative, and full of real-world relevance. Thanks for putting in the effort to make such a comprehensive and valuable resource. Looking forward to more content like this!